XSLT를 사용하여 오픈오피스의 편집기능 확장하기
오픈오피스가 무엇인지는 다들 알 것이다. (모르시는 분들은 살짝 검색을 -ㅁ-)
무엇이든지 오픈되어 있다는 것은 입맛대로 커스터마이징이 가능해진다는 점이 가장 큰 장점이다.
XML로 저장된 데이터로 워드 프로세싱 문서를 만들기 위해 필터를 만들 수 있다.
이번 Article은 튜토리얼(Tutorial)로 이루어져 있어 난이도는 중급에 속하나, 크게 어렵지 않을 것이다.
오픈 오피스에는 가져오기/내보내기(Import/Export)필터 기능이 존재하는데, 이것을 사용하여 일반 문서인 XML데이터를 열 수 있는 방법을 다룬다. 이를 이용하면 사용자들은 더욱 자연스럽게 문서를 편집하고,
이를 네이티브 포맷으로 다시 저장할 수 있게 된다. 또한 이 특징을 사용하여 문서를 XML데이터로 쉽게 변경이 가능해 진다.
XML 파일 포맷의 구문에 익숙하고 XSLT(XML Style Language Transformations)를 조금 다루어 본 사람이라면 오픈오피스를 XML 기반 데이터를 위한 맞춤 편집기로 사용할 때 그 발전가능성은 무궁무진하다.
이 튜토리얼에서는 XSLT필터 파일과 함께 작동하여 플러그인에서 XML형식으로 된 어떤 데이터라도 지원할 수 있도록 한다. 즉, 데이터를 기계가 처리하기 좋은 XML로 저장하면서 이를 사람에게 편한 방식으로 편집할 수 있다는 것이다. 전자는 쉬운 검색, 의미 맥락(semantic context)과 정보 찾아오기를 가능케 하고 후자는 더 높은 수준의 하이퍼텍스트 환경에서 효율적인 편집을 가능하게 한다.
먼저 XSLT에 대해서 조금 알아보자 (Article에서는 XSLT를 알고 있다는 전제를 하고 있으므로)
XSLT는 XML문서에 XSLT를 적용하여 또다른 XML, HTML, TXT등으로 변환하는 방법을 기술한 표준 방법이다. 확장 스타일시트 언어(XSL)의 확장으로서 XML문서가 다른 데이터 형식으로 재구성되는 방법이라고 간단히 보면 된다. 자세한 내용을 일일이 열거하기에는 어렵고 XSL에 대한 이해가 부족한 사람은 아래 링크에서 간단히 학습을 하면 이번 튜토리얼을 따라하는데 큰 어려움이 없을 것이다.
IBM XSLT 입문 : http://www.ibm.com/developerworks/kr/library/tutorial/x-xsltopenoff/section3.html
Lecture #1 : http://cafe.naver.com/javalove/217
Lecture #2 : http://cafe.naver.com/javalove/218
Lecture #3 : http://cafe.naver.com/javalove/219
Lecture #4 : http://cafe.naver.com/javalove/220
이제 XSL이 무엇인지 어느정도 이해할 수 있을 것이다. 그럼 이번 튜토리얼을 따라하기 위해,
다음과 같은 것이 필요하다.
오픈오피스 2.0(+), 이번 예제에는 2.2를 사용한다. 리눅스 용, 윈도우 용 모두 상관없다.
XML편집기는 XML과 XSLT파일을 편집할 수 있어야 한다. 기본적인 Text Editor라면 상관없다 유닉스에서는 vim.
순서는 다음과 같이 진행된다.
- 개요
- XSLT입문
- 가져오기 필터
- 내보내기 필터와 다른 포맷으로 내보내기
- 요약
- 다운로드
- 참고자료
- 필자소개
튜토리얼이 자세하게 나와 있어(XSL에 대한 부분이 조금 약하긴 하지만), 1시간만에 튜토리얼을 따라할 수 있었다. XML의 모든 장점을 가지면서도 리치 텍스트 편집을 쉽게 가능하게 해 준다.
XML을 사랑하고 오픈오피스를 사용하는 사람이라면, 한번쯤 꿈꿔본 일이 아닐까.
또한, XSLT를 사용하면 편집된 문서를 어떻게 XML이 아닌 포맷으로 내보낼 수 있는지도 설명되어 있다.
XML이라는 것을 가장 처음 접했을 때가 00년도였다. 7년이 지난 지금 XML의 중요성은 날이갈 수록 증대되고 있는데 웹의 발전과 더불어 XML은 의외로 많은 것들을 가능하게 해 줄 것이다.
이전에 리뷰했던 VXML또한 그것의 일부가 아닐까?
다음 링크를 클릭하고, 커피 한잔, 그리고 비스켓을 씹으면서 따라해 보자-
링크 : http://www.ibm.com/developerworks/kr/library/tutorial/x-xsltopenoff/index.html
'IBM dW review' 카테고리의 다른 글
| [IBM dW Review] SOA 복합 비즈니스 서비스 구현 (등록자 권한부여 프로세스 구현) (0) | 2007.12.31 |
|---|---|
| [IBM dW Review] Ajax와 XML : 미디어용 Ajax (0) | 2007.12.31 |
| Ajax와 XML : 라이트박스(lightbox)용 Ajax (0) | 2007.11.30 |
| 음성 실행 XML 개발하기 (Part 1, 2, 3, 4) (0) | 2007.11.28 |
| pureQuery : 자바 데이터베이스 애플리케이션을 작성하는 IBM의 새로운 패러다임 (0) | 2007.10.31 |
Ajax와 XML : 라이트박스(lightbox)용 Ajax
11월 6일 IBM dW에 업데이트된 기사로, PHP, Dynamic HTML(DHTML), Asynchronous JavaScript + XML(Ajax)와 같은 기술들을 사용하여 사용자의 관심을 끌 수 있는 컨텐츠를 만드는 방법이다.
먼저 결과 화면부터 보자.
텍스트에 적용된 결과이다. 마우스를 텍스트 위에 올려 놓으면, 우측의 그림처럼 작업 팝업과 같은 형식으로 마치 툴팁과도 같은 모습을 보여준다.


체험하기 : http://www.muttmansion.com/lightbox/tooltips/
다음은 이미지에 적용된 결과이다. 이 그림을 클릭할 경우, 우측의 그림처럼 섬네일의 원래 크기의 이미지가 창 중앙에 디스플레이 된다. 더욱이 백그라운드의 모든 Material이 흐려지기 때문에, 사용자는 중앙의 컨텐츠에 더욱 집중할 수 있다.


체험하기 : http://www.muttmansion.com/lightbox/lightbox/
또한 다음과 같이 페이지 자체적으로 윈도우용 컨텐츠를 가지고 있고, 사용자가 폼에서 Login버튼을 클릭하면 Ajax.Request 객체를 사용하여 서버에서 로그인을 요청한다. 그래서 우측의 그림처럼 매우 참신한 Web2.0 스타일의 로그인 윈도우를 볼 수 있게 된다.
이러한 방식은 애플리케이션에 팝업을 가져올 수 있고, 사용자들에게 웹 보다는 데스크탑 애플리케이션과 비슷한 것을 사용하고 있다는 인식을 줄 수 있다는 점이 매력적이다.


체험하기 : http://www.muttmansion.com/lightbox/window/
이러한 방식으로 자신의 웹 페이지에 유저들의 관심을 효과적으로 끌 수 있는 방법들을 다루고 있는데, 모든 예제는 Prototype.js JavaScript 라이브러리를 기반으로 구현한다.
첫번째 예제는 너무나도 간단하다. 먼저, 보여줄 페이지(index.html)를 구성하되, 마우스가 롤오버 되었을 경우 효과를 보여줄 텍스트를 <div>태그로 감싸주고 이름을 설정한다. 두번째로 롤오버 되었을 경우에 보여줄 텍스트를 text.php에 추가한다. 세번째로, JavaScript를 정의하는데,
<script type="text/javascript">
new Ajax.Updater( 'popup1', 'text.php' );
new Tooltip('설정한 div 이름', 'popup1')
</script>
이것으로 끝이다. 너무나 간단하지 않은가- 자신의 블로그에 굳이 다른 페이지를 통해 표시할 필요가 없는 각종 Contents들은 이러한 방식으로 간단히 표현가능하게 해 주며, 사용자의 관심도 끌 수 있다.
이런식으로 페이지를 어지럽히지 않고 사용자들에게 Contents를 On Demand 방식으로 상세한 내용을 보여줄 수 있으며, 상세한 내용은 텍스트 뿐 아니라 이미지, 테이블 포멧팅 등이 될 수도 있다.
가장 기본적인 예제를 맛보았는데, 상단에서 볼 수 있는 다른 예제들은 IBM dW에서 직접 보도록 하자.
그 외에도 '페이더(fader) 메시지'에 대한 예제도 볼 수가 있는데 html과 JavaScript에 대한 기본적인 이해만 있으면 어렵지 않게 구현할 수 있을 것이다.
또한 이는 모듈 겸, 프레임웍 같이 되어 있어 활용성도 높을 듯 하다.
링크 : http://www.ibm.com/developerworks/kr/library/x-ajaxxml6/index.html
또한, 이것을 그대로 적용한 예제들도 볼 수가 있는데, 아래 링크를 따라가 보자.
링크 : http://www.huddletogether.com/projects/lightbox2/
각자 자신의 블로그에 멋진 이미지 갤러리 하나씩 삽입 해 보는것도 괜찮지 않을까 싶다.
'IBM dW review' 카테고리의 다른 글
| [IBM dW Review] Ajax와 XML : 미디어용 Ajax (0) | 2007.12.31 |
|---|---|
| XSLT를 사용하여 오픈오피스의 편집기능 확장하기 (0) | 2007.11.30 |
| 음성 실행 XML 개발하기 (Part 1, 2, 3, 4) (0) | 2007.11.28 |
| pureQuery : 자바 데이터베이스 애플리케이션을 작성하는 IBM의 새로운 패러다임 (0) | 2007.10.31 |
| HTML 5의 새로운 엘리먼트 (New element in HTML 5) (0) | 2007.10.24 |
음성 실행 XML 개발하기 (Part 1, 2, 3, 4)
논문 심사도 끝났겠다, 막바지 포스팅 그 첫번째-_ - 이거 완전 벼락치기 아닌가.. ㅠㅠ
IBM developerWorks에서 일전에 꽤나 흥미롭게 읽어 보았던 음성 실행 XML 에 관련된 기사가 Part4를 마지막으로 연재가 종료되었는데 Part1, 2, 3, 4의 근간이 되는 VXML에 대해서 간단히 알아보고, 이 중 하나에 대해서 좀 더 알아보기로 하자.
키워드는 VXML이다.
VXML은, VoiceXML 이라고 하는데, XML Output 표준에 주어진 이름이며 파일 포멧은 VXML이다.
VXML은 VoiceXML Content를 텍스트[Text-To-Speech (TTS)]로 변환하는 VoiceXML 브라우저와 결합하며, 음성 명령을 인식하는 것 또한 가능하다. (IBM dW)
VXML은 XML의 일종으로, 대화형 음성입출력 방식을 규정한 국제 표준 기술이며, 1999년 3월에 AT&T, IBM, 모토로라, 루슨트테크놀러지 등의 주도로 'VoiceXML 포럼'이 발족됐고 2000년 5월에 W3C에 의해 WWW의 대화형 Markup Language 표준으로 공인되었다.
VXML은 음성 서비스 시나리오 저작자를 갖가지 문제에서 해방시켜 서비스 내용 그 자체에만 집중할 수 있도록 해 준다. 지금까지 음성 서비스 구현과정과는 달리 VXML문서로 음성 서비스 시나리오를 작성한 사람은 음성 입출력의 기술적인 문제에 대해 거의 알 필요가 없기 때문이다.
또한, 시나리오를 통해 전달할 정보의 창출과정이나 수집한 정보의 처리과정은 웹서버에 연결된 CGI나 DB등을 통해 가능하므로 대화 시나리오 저작자는 서비스 로직으로부터 독립될 수 있다. 쉬운 저작이 가능하고 온갖 복잡한 상황을 표현하기에 별다른 어려움이 없는 VXML의 문법체계 또한 저작자에게 큰 도움이 된다.
나아가 VXML은 컨텐츠 구축에 소요되는 인력을 크게 줄여 음성 포털의 실현을 가능하게 해 줄 것으로 기대된다. 또한 VXML 문서형식은 XML에 내포된 태그 형식을 갖는 텍스트 파일로서 읽기 쉽고 의미가 명확하며, 프로그래밍을 경험해 본 사람이 조금만 노력을 기울이면 쉽게 작성할 수 있다.
게다가 많은 이들이 설치 운용하고 있는 웹서버를 문서 서버로 이용하기 때문에 음성 서비스 시나리오 저작의 저변 확대 및 대중화가 가능해, 개인 음성서비스의 구축 붐이 일어날 가능성이 대단히 높다. 이것은 결국 전문적인 음성 시나리오 작가의 등장과 음성 서비스 수준의 고급화로 이어지게 될 것이다.
이러한 맥락에서, 이번 IBM developerWorks의 이번 Article Part1, 2, 3, 4는 VXML을 이용하여 각종 예제를 접할 수 있다는 점에서 상당히 의미가 있다.(기술 설명만 아무리 많으면 뭐하나, 예제가 있어야 심화 문제를 풀지-_-)
현재, VXML을 이용한 예제 중 업데이트 된 4개의 Article이다. 이 중, 개인적으로 가장 관심있는 부분은 Part4의 '음성 실행 Yahoo 검색 애플리케이션'이다.
Part4는 VXML을 사용하여 검색하고, 리턴된 검색 결과를 듣는 것도 가능하다. Part4에서는 이러한 일을 수행하는 애플리케이션을 구현한다. 다음은 웹 검색 워크플로우이다. 그림에서 알 수 있듯이 2개의 메뉴를 제공하는데, 로컬 검색(List local search phrases)과 전통적인 웹 검색(List Web search phrases)이 그것이다. 전자는 두개의 인풋 값, 검색어, 위치를 필요로 하고, 후자는 검색어만 필요로 한다. 검색 결과는 VXML로 변환되어 반환된다.
이후로, 자유 형식 문법 인풋을 만들고, 기본적인 VXML 아웃풋 클래스를 만든다.
그리고 기본 인터페이스를 사용하여 간단한 검색을 출력하고 VXML 아웃풋을 살펴보게 된다.
그리하여 Yahoo 검색 인터페이스를 사용하여 웹 검색을 실행하게 되는데, 솔직히 따라하는데 애를 좀 먹었다.
하지만, 어렵다는 이야기는 아니다. 조금 구체적인 설명이 있었으면 하는 부분도 없잖아 있었지만, 그럭저럭 프로그래밍에 대한 지식이 조금 있다면 어렵지 않게 가능할 것이다.
그리고 Article에서도 있듯이, 아웃풋의 음성 버전이 완벽하지 않다.
하지만 이것으로도 충분하다.
이를 이용하면, 전화를 통해 음성으로 쇼핑, 검색, 개인일정관리 등의 서비스가 가능하게 되며,
이는 말(Voice)로 인터넷 서비스를 이용하는 보이스 포털로도 연결될 수 있다.
이같은 서비스를 가능하게 해 주는 기본 기술 중 하나가 음성인식(ASR: Automatic Speech Recognition)과 VXML이다. VXML을 접하고 가장 먼저 생각한 것은 개인일정관리이다.
사실, 일정관리를 편리하게 하려는 시도는 도처에서 너무나 많이 시도되었었고 지금도 진행중이다.
하지만 개인일정을 완벽하게 관리하기 위해서는 관리도구가 항상 근처에 있어야 하는데 연필로 종이에 기록하는 것은 불편하다 하여, 전자수첩이나 휴대폰, 웹 등의 도구를 사용하게 되었으나, 휴대폰과 전자수첩은 버튼을 눌러 기록/검색하는 것이 시간이 많이 걸리고, 웹은 휴대할 수가 없기 때문에 기록이 용이하지 않다.
이를 해결할 수 있는 방법은 음성인식 뿐이다.
일정의 입력이 필요할 경우, 음성으로 입력하고, 검색이 필요할 경우에도 음성으로 검색, 결과 또한 음성으로 알려줄 수 있다는 점에서 VXML을 이용한 이번 예제는 상당히 의미가 있다.
한번 따라 해 보면 좋을 성 싶다. 그리고 재미있고 신기하다.
몇몇 관심있는 녀석들로 팀을 구성해서 음성인식 개인일정관리에 한번 도전해 보는 것도 좋을 법 하다.
물론 여유 시간이 좀 나야 가능하겠지만, 흐흐.ㅠㅠ
※ 관련 기사의 링크는 상단의 Part1, 2, 3, 4에 각각 링크되어 있습니다.
'IBM dW review' 카테고리의 다른 글
| XSLT를 사용하여 오픈오피스의 편집기능 확장하기 (0) | 2007.11.30 |
|---|---|
| Ajax와 XML : 라이트박스(lightbox)용 Ajax (0) | 2007.11.30 |
| pureQuery : 자바 데이터베이스 애플리케이션을 작성하는 IBM의 새로운 패러다임 (0) | 2007.10.31 |
| HTML 5의 새로운 엘리먼트 (New element in HTML 5) (0) | 2007.10.24 |
| DWR을 사용하여 Ajax 기반 파일 업로드 포틀릿 개발하기 (0) | 2007.10.18 |
pureQuery : 자바 데이터베이스 애플리케이션을 작성하는 IBM의 새로운 패러다임
IBM developerWokrs에 pureQuery라 하는 새로운 패러다임이 소개되었다.
자세한 내용을 알기 위해서는 해당 Article을 읽어 보기를 권하지만, 간단히 말하면 다음과 같다.
JAVA에서 DB APP를 작성하기 위해서는 DB에 SQL Query를 날리고, 그 결과로 전송된 데이터를 기초로 APP를 작성하게 되는 전통적인 방식에서 벗어나, pureQuery는 GUI기반의 방식을 제공하여 설계와 구현단계에서 혁신적인 생산성 향상을 보장한다.
가장 주목할 만한 점은 데이터의 액세스와 조작을 위해 관계형 데이터를 JAVA의 객체로 자동 변형을 수행한다는 점이다. 한편, 이러한 객체들은 일반적인 객체지향 프로그래밍 패러다임에서 활용되어 비즈니스 로직과 기반 코드를 작성한다. pureQuery의 기능은 쿼리 언어를 JAVA와 통합함으로서 전통적인 JDBC 프로그래밍을 효과적으로 개선한다.
이 기사는 다음과 같은 순서로 진행된다.
- pureQuery란?
- quick tour
- 데이터베이스 중심 객체화(DDO) 케이스 시나리오
- 쿼리 중심 객체화(QDO) 케이스 시나리오
- 객체 관계형 매핑(ORM) 케이스 시나리오
- pureQuery의 콘텐츠 어시스트와 자바 에디터와의 긴밀한 통합
- 디자인 및 러나임 핸드쉐이크(hand-shaking)
- 결론
- 참고자료
- 필자소개
JAVA를 다루어 본 적이 별로 없어서, eclipse는 거의 문외한인데 최근 JAVA를 이용할 일이 많아졌다.
좀 더 일찍 알았다면, 지금 하고 있는 DB PROJECT를 이걸로 한번 해 보는건데 아쉽다.
취업 시즌이라 상당히 바쁘다 -_ - (과연 취업이나 할 수 있을런지. . .)
짬이 나는데로 이것부터 한번 해 봐야겠다.
매력적인걸?
pureQuery : 자바 데이터베이스 애플리케이션을 작성하는 IBM의 새로운 패러다임
http://www.ibm.com/developerworks/kr/library/dm-0708ahadian/
'IBM dW review' 카테고리의 다른 글
| Ajax와 XML : 라이트박스(lightbox)용 Ajax (0) | 2007.11.30 |
|---|---|
| 음성 실행 XML 개발하기 (Part 1, 2, 3, 4) (0) | 2007.11.28 |
| HTML 5의 새로운 엘리먼트 (New element in HTML 5) (0) | 2007.10.24 |
| DWR을 사용하여 Ajax 기반 파일 업로드 포틀릿 개발하기 (0) | 2007.10.18 |
| PHP와 Sphinx로 내 사이트에 특화된 커스텀 검색엔진 구현하기 (0) | 2007.10.08 |
HTML 5의 새로운 엘리먼트 (New element in HTML 5)
HTML의 확장된 버전 지원 여부를 결정하기 위해 자료를 찾다 보니 왠걸, developerWorks가 걸렸다.
비록 번역되지 않은 Article이긴 하지만, 상관없다.
HTML 5에서 달라지는 점은 크게 3가지 이다. 먼저 웹 브라우저 마다 기존의 HTML을 해석하는 방식의 차이에서 오는 혼란을 없애기 위해 구현 방식을 상세하게 기술한 점이다.
기존 HTML의 하위 호환성은 제공하면서 <!doctype html>라는 새로운 DOCTYPE을 가진 경우 각 요소와 속성에 대한 웹 브라우저의 동작 방식이 명확하게 정의했다. 전체 표준안의 상당 부분이 여기에 해당한다.
두 번째는 새로운 HTML 요소를 대거 도입하고 콘텐츠 구조에 불필요한 요소와 속성들을 제거 했다. 웹 문서를 구조적으로 제공 가능한 <header>, <nav>. <footer> 같은 태그를 포함하였고 시간, 측정 단위 등 의미를 살린 <time>. <m> 태그 등이 추가 되었다. 대표적인 스타일 요소인 <font>. <strike>와 align이나 background, bgcolor 같은 속성은 더 이상 사용할 수 없다.
HTML에서 달라지는 가장 대표적인 특징은 웹 애플리케이션 개발용 스펙들이다. 가장 대표적인 것이 WebForm에서 다양한 속성들을 추가한 것이다. <input> 태그에 datetime 속성을 넣어주면 웹 브라우저가 자동으로 달력을 표시해 준다. 또한 IE에서만 사용 가능 했던 CONTENTEDITABLE 속성이 표준화 되어 모든 HTML 요소를 사용자가 직접 편집할 수 있게 된다. 특히 innerHTML, embed 같이 많이 사용하면서도 비 표준 영역에 있었던 것들이 대거 포함된다.
뿐만 아니라 HTML 요소의 드래그앤 드롭, 오디어 비디오 표시, 벡터 그래픽 표시를 위한 각종 요소들을 새로 도입 했다. 그러면서도 <b>, <i> 같은 대표적인 HTML 요소는 없애지 않고 각각 제품명 키워드 같은 강조 요소와 동식물 학명 같은 이탤릭체에 사용하도록 재정의 했다.
HTML 5에 새로 도입된 엘리먼트는 다음과 같다.
- 구조적 엘리먼트 : aside, figure, section
- 인라인 엘리먼트 : time, meter, progress
- 임베딩 엘리먼트 : video, audio
- 인터렉티브 엘리먼트 : details, datagrid, command
각각의 자세한 설명과 사용 예 등을 확인하고 싶다면, 다음 링크로 이동하자.
http://www.ibm.com/developerworks/kr/library/x-html5/index.html
추가적으로, 현재 국내에는 Ajax, SilverLight, AIR 등 각종 리치 인터넷 기술이 웹 APP의 미래인 듯 포장되고 있는 감이 없지 않다. 하지만 우를 범해서는 안되는 것이 웹은 정보 전달의 수단으로 기본에 충실하면서 애플리케이션 기능을 제공할 수 있어야 한다는 점이다.
사용자 경험은 담보로 기존 웹의 장점들을 낡은 기술로 치부해서는 안 된다.
이는 브라우저 벤더들 몫만이 아니다. 누구나 정보와 기능 모두를 제공할 수 있도록 웹의 컨텐츠를 만들고 생산하는 모든 저작자들과 리치 웹 서비스를 만드는 사람들의 책임이다. HTML5가 중요한 것은 이러한 표준 웹의 근본적인 변화가 시도되고 있기 때문이다.
HTML5 REF : http://www.ibm.com/developerworks/kr/library/x-html5/index.html
참고 : 윤석찬(다음 R&D센터) 님의 기사 : http://channy.creation.net/blog
'IBM dW review' 카테고리의 다른 글
| Ajax와 XML : 라이트박스(lightbox)용 Ajax (0) | 2007.11.30 |
|---|---|
| 음성 실행 XML 개발하기 (Part 1, 2, 3, 4) (0) | 2007.11.28 |
| pureQuery : 자바 데이터베이스 애플리케이션을 작성하는 IBM의 새로운 패러다임 (0) | 2007.10.31 |
| DWR을 사용하여 Ajax 기반 파일 업로드 포틀릿 개발하기 (0) | 2007.10.18 |
| PHP와 Sphinx로 내 사이트에 특화된 커스텀 검색엔진 구현하기 (0) | 2007.10.08 |
DWR을 사용하여 Ajax 기반 파일 업로드 포틀릿 개발하기
하지만, 대용량의 파일 업로드를 안정적으로 수행하기 위해서는 ActiveX 따위의 컴포넌트를 필요로 했다.
특히나, 전송 진행 상태를 표시하기 위해서는 더더욱 그러했다.
웹에서 검색을 하고, 필요한 데이터를 내려받기 위해서 특정 웹사이트는 다운로드용 ActiveX를 설치하도록 요구하는데, 다음에 또 방문할지 알 수 없는 일회성인 곳이라면 더더욱 설치하기가 싫어지는 것은 사실이다.
DWR을 사용하여 Ajax기반의 파일 업로드를 작성/이용하면, 클라이언트는 ActiveX와 같은 지저분한 컨트롤을 설치 할 필요가 없을 뿐 아니라, 포틀릿을 통해 서버는 진행 상태를 서버측에서 검색하고, 클라이언트도 진행 상태를 디스플레이 할 수 있다.
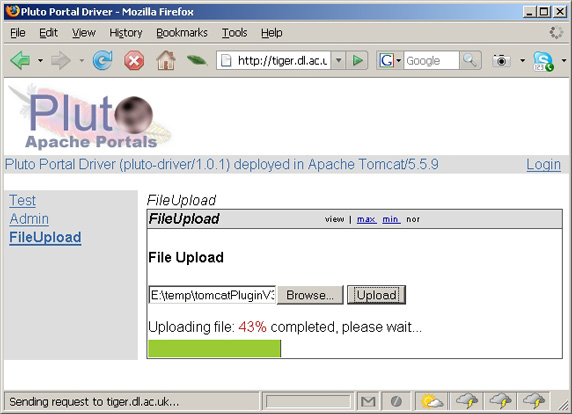
물론, 파일 업로드 진행 시 서버와 클라이언트 간 통신은 Ajax를 사용하여 구현된다.
또한 DWR(Direct Web Remoting)는 웹 개발 프로세스를 가져오는데 이상적인 프레임워크로서, 서버사이드 빈과 자바스크립트 그리고 DWR 서블릿으로 구성되어 있는 아파치 라이센스를 가진 라이브러리 이다.
말 그대로 서버에 존재하는 클래스를 마치 로컬에서 호출하듯이 사용하게 해 주는 것이라면 이해가 될런지?
마치 RMI와도 흡사한 DWR은 서버의 자바클래스와, 클라이언트의 자바스크립트의 원격호출기능을 정의한다. 서버에 Cart라는 클래스가 있고, get CartItem이라는 메소드가 있다면, 클라이언트의 스크립트 상에서 똑 같은 객체명 Cart.getCartItem()으로 호출하여 리턴값을 사용할 수 있게 된다.
그러면 DWR 서블릿은 또 무엇이며, 서버사이드 빈은 또 무엇인가?
DWR 서블릿 - 일종의 맵퍼, 후킹 과 같은 DWR만의 컨트롤인데 라이브러리를 연결하고, 초기로딩시 올라올 수 있게 몇몇 설정만 간단히 하면 된다. 주요 기능으로는 스크립트 자동 제네레이션이나, 데이터 이동 등의 역할을 하는 컨트롤러라 생각하면 된다.
서버사이드 빈 - 서버와 클라이언트 사이을 오고갈 빈즈이다. DWR이 서버에 있는 빈을 자바스크립트로 자동 변환작업을 해 주어, 클라이언트 스크립트에서 마치 자신의 클래스를 쓰는 것 처럼, 각종 값들을 가져올 수 있게 한다. 실제로 작성해야 하는 것들 이다. (참고 : 자바사랑 까페)
그럼, DWR을 이용해서 Ajax기반의 파일 업로드 포틀릿(웹 컴포넌트)를 제작해 보자.
http://www.ibm.com/developerworks/kr/library/wa-aj-dwr/
'IBM dW review' 카테고리의 다른 글
| Ajax와 XML : 라이트박스(lightbox)용 Ajax (0) | 2007.11.30 |
|---|---|
| 음성 실행 XML 개발하기 (Part 1, 2, 3, 4) (0) | 2007.11.28 |
| pureQuery : 자바 데이터베이스 애플리케이션을 작성하는 IBM의 새로운 패러다임 (0) | 2007.10.31 |
| HTML 5의 새로운 엘리먼트 (New element in HTML 5) (0) | 2007.10.24 |
| PHP와 Sphinx로 내 사이트에 특화된 커스텀 검색엔진 구현하기 (0) | 2007.10.08 |
PHP와 Sphinx로 내 사이트에 특화된 커스텀 검색엔진 구현하기
운영중인 사이트가 일정 크기 이상으로 방대해지면, 사용자로 하여금 원하는 정보의 접근성이 떨어지게 된다.
그럴 경우 사용자들은 대개 검색을 이용하게 되는데, 사이트 자체에서 검색 기능을 제공하지 않는다면, 원하는 정보가 어디에 있는지 찾기가 힘들게 된다.
구글에서는 특정 사이트를 대상으로 검색을 하는 기능도 제공하고 있으나, 보다 구체적인 검색 결과를 만들어 낼 수가 없으며, 모든 사이트에 잘 맞는것은 아니라는 점에서 사이트 자체적으로 검색 기능을 제공하는 것이 좋다.
또한 자기 사이트에 특화된 검색 기능을 제공하려면, 데이터 소스와 그 소스를 검색해야 하는데, 웹APP의 경우, 일반적으로 관계형 DB이다. 그러나 일부 검색들은 DB가 수행할 수 있는 것 보다 더 특화되어 있거나, 검색이 너무 복잡해 질 경우에는 SQL의 JOIN 연산으로는 벅찬 것이 사실이다.
여기서는 무료인데다, 오픈소스 검색엔진인 Sphinx를 대안으로 삼는다. 장점으로는 텍스트를 매우 빠르게 검색하는데 있는데, 예를 들어, 다섯 개의 인덱스 컬럼과 약 30만 개의 행을 가진 활성 데이터베이스에서, 각 컬럼은 15단어를 포함하고 있다면 Sphinx는 "any of these words" 검색 결과를 100분의 1초 안에 찾아낸다.
(2-GHz AMD Opteron Prosessor, 1GB RAM, Debian Linux® Sarge)
그 외에도 Sphinx는 많은 장점들을 가지고 있는데, Spninx와 PHP를 이용하여, 자신의 사이트에 특화된(!!) 검색 엔진을 장착할 수 있다는 점은 굉장한 매력이지 않은가?
다음은 IBM developerWorks의 Article로 업데이트 된 지 일주일도 되지 않은 따끈따끈한 Article이다.
예제로 자동차의 부품을 판매하는 사이트에 특화된 검색 엔진을 만드는 방법에 대해 자세히 설명하고 있는데, 대충의 방법론만 말하고 있는 것이 아니라, 기본적으로 자동차 부품을 판매하는 사이트의 데이터들부터 규정하고, 일반적인 검색의 비용을 산출하고 그것이 왜 비효율적인지를 분석하며, 그 대안으로 Sphinx를 제시하고 있다.
본문의 내용을 빌리자면,
' 인터넷 시대에, 사람들은 패스트 푸드와 같은 형태의 정보를 원한다. 즉각적으로 제공되고, 노력을 들이지 않아도 되며, 적당한 크기(Byte-size)로 제공되는 음식을 원한다. 실제로 인내심 없고 배고픈 대중들의 구미에 맞추려면, 웹 사이트는 바로 효과가 나타나는 포멧을 제공해야 한다 '
이러한 맥락에서 Sphinx를 이용하여 특정 웹사이트에 특화된 검색 서비스를 구현할 수 있고, 그 것의 효율 또한 우수하다면, 한번 쯤 구현해 볼 만한 가치가 있지 않을까?
시간나는 틈틈히 나의 블로그를 대상으로 구현을 해 본 결과, 적어도 Sphinx PHP API문서 쯤은 구해 놓고 시작하는 것이 도움이 될 지도 모르겠다.
요 근래 각종 기업들에서 제공하는 openAPI를 이용한 매시업이 인기를 끌고 있는데, 거대한 포털의 DB에서 openAPI들의 조합들로 자신이 주기적으로 원하는 데이터들만을 추출하여 보고자 할 때에도, 간단하게 구현할 수 있는 이 Sphinx는 추출된 데이터들을 대상으로 효과적인 검색을 수행할 수 있다고 생각한다.
이를 어떻게 응용하느냐는 물론, 사용하는 사람들의 몫이겠지만 말이다.
http://www.ibm.com/developerworks/kr/library/os-php-sphinxsearch/
REF.
http://www.sphinxsearch.com/doc.html#installation [Sphinx Installation]
http://www.ibm.com/developerworks/kr/views/opensource/articles.jsp?expand=&sort_order=desc&search_by=php&show_abstract=true&sort_by=%EB%82%A0%EC%A7%9C&view_by=Search [PHP 기술자료 - IBM developerWorks]
'IBM dW review' 카테고리의 다른 글
| Ajax와 XML : 라이트박스(lightbox)용 Ajax (0) | 2007.11.30 |
|---|---|
| 음성 실행 XML 개발하기 (Part 1, 2, 3, 4) (0) | 2007.11.28 |
| pureQuery : 자바 데이터베이스 애플리케이션을 작성하는 IBM의 새로운 패러다임 (0) | 2007.10.31 |
| HTML 5의 새로운 엘리먼트 (New element in HTML 5) (0) | 2007.10.24 |
| DWR을 사용하여 Ajax 기반 파일 업로드 포틀릿 개발하기 (0) | 2007.10.18 |
